Deployed a Mastodon Instance at Home
P.S: My Mastodon account: @nyanshell@mastodon.nyanshell.com
Several years ago, I took a glimpse of Mastodon and thought I could deploy one. However, I soon forgot this matter. But recent news about Twitter makes me realize maybe it’s better to have a Twitter alternative. So after a long time of procrastination, I finally decided to deploy a Mastodon instance.
Why self-hosted: Because it’s cool. There’re many public Mastodon instances that let you create an account freely. You still need to follow their site ToS, and most of them don’t have an SLA. Since I’m using a decentralized service, deploying it myself is an interesting part(Maybe the most!), and it’s a good chance to get familiar with the ecosystem.
Service Architecture After Deployment
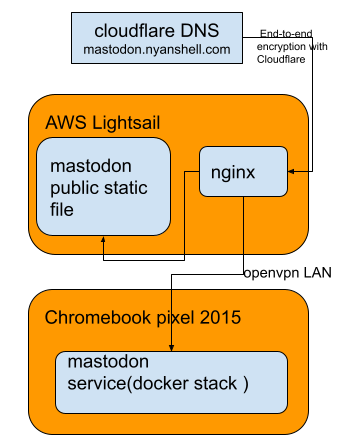
Deploy Mastodon Instance Using Docker Swarm
Mastodon is a Ruby-written web application which relies on PostgreSQL, Redis, Elasticsearch(optional for text search). Deployment could become complicated without proper orchestration. Luckily they provide a YAML configure file for docker-compose in the repo, so we could just change some configuration and the whole service could start smoothly(almost). I just followed up instructions from these blogs to complete my deployment at my home server(Chromebook pixel 2015, 16GB i7-5500U):
- Running Mastodon with docker-compose
- Mastodon Docker Setup
- Mastodon Setup with Docker and nginx-proxy
- Install Mastodon in Docker Swarm
- Mastodon Docker Setup
Main steps:
- Clone the repo of Mastodon.
- Generate secret and fill into
.env.production:docker run -it tootsuite/mastodon bundle exec rake secret - configure
.env.production(LOCAL_DOMAIN, hostname of services,SECRET_KEY_BASE) docker-compose build- PostgreSQL init:
docker-compose run --rm web bundle exec rake db:migrate - Create admin user:
docker-compose run --rm web bin/tootctl accounts create <user-name> --email <email> --confirmed --role admin - Create Docker stack:
docker stack deploy mastodon -c docker-compose.yml
And there’re also some noticable adjustments:
- Folder permissions, see First Run part here.
- SMTP is not necessary if you don’t want the user registration feature(user management could complete via
tootctl) - Run elasticsearch docker container:
sysctl -w vm.max_map_count=262144See Install Elasticsearch with Docker for details. - Remove services’s
build .indocker-compose.ymlif you don’t want to build instances from scratch(apt install may have some version issues because of some outdated package version info).
After the deployment, validate the services status with docker service ls command. If anything goes wrong, see what happened inside the container via docker logs <container-name>.
Nginx & Cloudflare Configuration
Next is to config Nginx on AWS lightsail. Because I don’t want to maintain a short period cert for TLS(e.g.: Let’s Encrypt) and expose my VPS’s IP, I chose Cloudflare’s end-to-end encryption mode. In this mode, Cloudflare gives you a self-signed certificate to communicate your server with Cloudflare, and the browsers also visit Cloudflare with encrypted traffic:

Mastodon also provide a Nginx sample config. I only changed backend & streaming server’s IP and updated some config about SSL:
- location / { return 301 https://$host$request_uri; }
+ ssl_certificate /etc/ssl/cloudflare.cert.pem;
+ ssl_certificate_key /etc/ssl/cloudflare.key.pem;
+ ssl_client_certificate /path/to/authenticated_origin_pull_ca.pem;
+ ssl_verify_client on;
Here I removed 301 redirect to avoid redirect loop error. And obviously, I don’t need a redirect when communicating with Cloudflare’s proxies. However, I wasted lot of time here.
Besides that, I also copied files in mastodon/public folder to serve js & css files.
Finally, I tried to log in with my admin account to see if everything went right, and then I found some permission issues in the postgreSQL and Redis(I missed folder privilege adjustment before). After that, everything goes smoothly.
Federation Relay
A federation relay is an intermediary server that exchanges large volumes of public posts between servers that subscribe and publish to it. It can help small and medium servers discover content from the fediverse, which would otherwise require local users manually following other people on remote servers.
I found there’re many rely servers following ActivityPub protocol could help your site switch information with other instances. I added some top servers, and then the Federated timeline amplified with lots of toots(But there is a rate limit for the federated timeline).
Issues & TODOs
- Automatically online backup: Since I use LVM in my home server, maybe I could do the usual trick to make LVM snapshot periodically and backup the whole folder to NAS. However, it needs some toil to write scripts and configuration.
- Public content storage:: To my surprise, the media content could occupy lots of disk space in a short time. After two days of the deployment, the media content already cost 7.71 GB (With only one active user on the server!). Because there’s only a 64GB soldered SSD on the Chromebook, the disk will run out soon. Maybe I should consider moving the content into NAS or making a cron job to clean up the cache every day.
Space cost in
publicfolder:620K public/system/accounts 9.0G public/system/cache 13M public/system/media_attachments 2.9M public/system/site_uploads
Conclusion
Performance
After two days of deployment, the service runs smoothly, and the system load isn’t increased much:
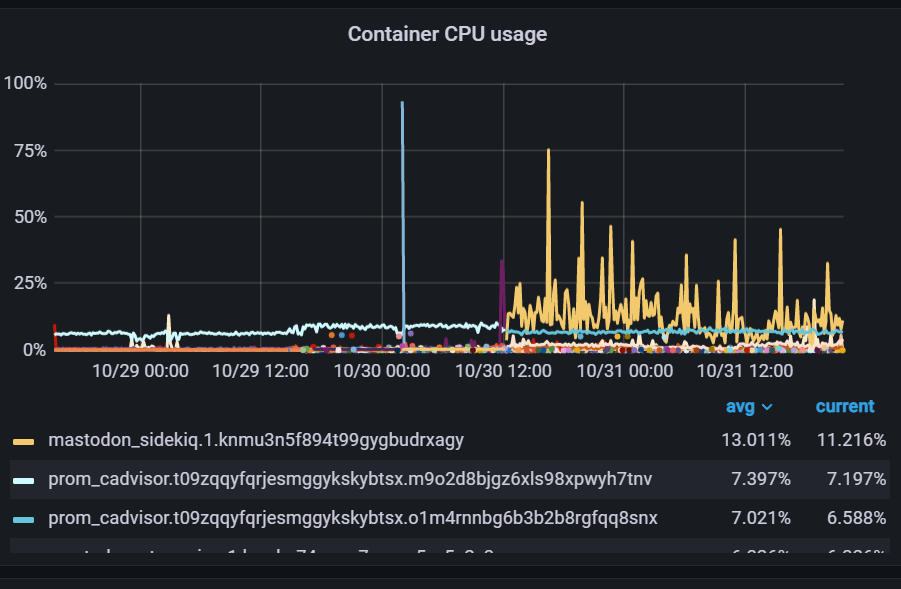
The increment of network traffic is acceptable, and the whole service occupied 4GB of memory(elasticsearch used around 2.6G):
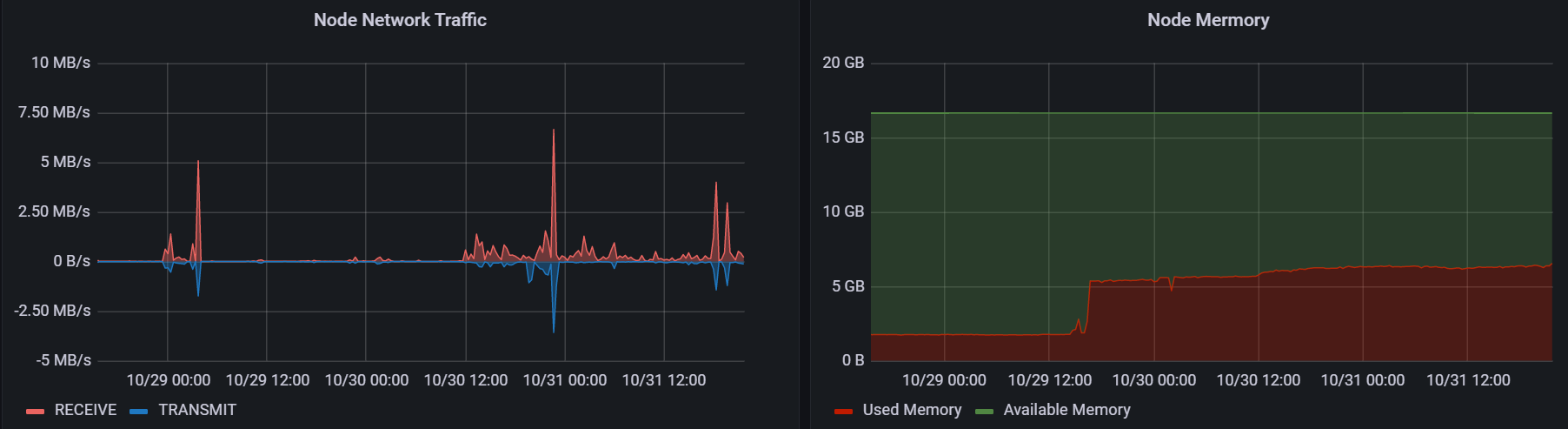
Seems it’s enough for the single account use case.
Deployment
Overall the whole deployment experience is good at modern microservice architecture. Especially it’s easy to create an isolated environment and do some experiments. However, if I want to make the service sustainable and decrease the risk of data loss, I need to do more investigation on Mastodon’s documentation. Because when I deploy services in this way, the details in the services are just like a blackbox (just like when I deploy LAMP services in university). Some service details (e.g., database configuration, indexes, user privileges) are easily neglected, and some issues from misconfiguration may show up in the future. Step-by-step deployment isn’t always convenient, but it always leads a peace of mind. After all, maybe I’m just not used to the docker toolchains. It’s obvious that IaC (infrastructure-as-code) could make services maintainable, and after several months I could also find what I had done before.